
Deepfake technology uses deep neural networks to convincingly replace one face with another in a video. The technology has obvious potential for abuse and is becoming ever more widely accessible. Many good articles have been written about the important social and political implications of this trend.
This isn't one of those articles. Instead, in classic Ars Technica fashion, I'm going to take a close look at the technology itself: how does deepfake software work? How hard is it to use—and how good are the results?
I thought the best way to answer these questions would be to create a deepfake of my own. My Ars overlords gave me a few days to play around with deepfake software and a $1,000 cloud computing budget. A couple of weeks later, I have my result, which you can see above. I started with a video of Mark Zuckerberg testifying before Congress and replaced his face with that of Lieutenant Commander Data (Brent Spiner) from Star Trek: The Next Generation. Total spent: $552.
The video isn't perfect. It doesn't quite capture the full details of Data's face, and if you look closely you can see some artifacts around the edges.
Still, what's remarkable is that a neophyte like me can create fairly convincing video so quickly and for so little money. And there's every reason to think deepfake technology will continue to get better, faster, and cheaper in the coming years.
In this article I'll take you with me on my deepfake journey. I'll explain each step required to create a deepfake video. Along the way, I'll explain how the underlying technology works and explore some of its limitations.
Deepfakes need a lot of computing power and data
We call them deepfakes because they use deep neural networks. Over the last decade, computer scientists have discovered that neural networks become more and more powerful as you add additional layers of neurons (see the first installment of this series for a general introduction to neural networks). But to unlock the full power of these deeper networks, you need a lot of data and a whole lot of computing power.
That's certainly true of deepfakes. For this project, I rented a virtual machine with four beefy graphics cards. Even with all that horsepower, it took almost a week to train my deepfake model.
I also needed a heap of images of both Mark Zuckerberg and Mr. Data. My final video above is only 38 seconds long, but I needed to gather a lot more footage—of both Zuckberg and Data—for training.
To do this, I downloaded a bunch of videos containing their faces: 14 videos with clips from Star Trek: The Next Generation and nine videos featuring Mark Zuckerberg. My Zuckerberg videos included formal speeches, a couple of television interviews, and even footage of Zuckerberg smoking meat in his backyard.
I loaded all of these clips into iMovie and deleted sections that didn't contain Zuckerberg or Data's face. I also cut down longer sequences. Deepfake software doesn't just need a huge number of images, but it needs a huge number of different images. It needs to see a face from different angles, with different expressions, and in different lighting conditions. An hour-long video of Mark Zuckerberg giving a speech may not provide much more value than a five-minute segment of the same speech, because it just shows the same angles, lighting conditions, and expressions over and over again. So I trimmed several hours of footage down to 9 minutes of Data and 7 minutes of Zuckerberg.
Faceswap: End-to-end deepfake software
Then it was time to use deepfake software. I initially tried using a program called DeepFaceLab and managed to produce a crude deepfake video using it. But when I posted on the SFWdeepfakes subreddit looking for information, several people suggested I try Faceswap instead. People pointed out that it offered more features, better documentation, and better online support. I decided to take their advice.
Faceswap runs on Linux, Windows, and Mac. It includes tools to perform every step of the deepfake process, from importing initial videos to generating a finished deepfake video. The software isn't exactly self-explanatory, but it comes with a detailed tutorial covering every step of the deepfaking process. That tutorial was written by Faceswap developer Matt Tora, who also provided me with excellent realtime chat support in the Deepfake Discord channel.
Faceswap requires a powerful graphics card; I knew my six-year-old MacBook Pro wasn't going to cut it. So I asked the Ars tech team to rent me a virtual Linux machine from a leading cloud provider. I started out using an instance with a Nvidia K80 GPU and 12GB of graphics memory. After a few days of training, I upgraded to a two-GPU model and then to a four-GPU monster. It had four Nvidia T4 Tensor Core GPUs with 16GB of memory each (it also had 48 vCPUs and 192GB of RAM that largely went unused because neural network training is so GPU-heavy).
Over two weeks of work, I racked up $552 in cloud-computing charges. I undoubtedly paid a premium for the convenience of renting my computing hardware. Faceswap's Tora told me that the "sweet spot" right now for deepfake hardware is a Nvidia GTX 1070 or 1080 card with at least 8GB of VRAM. You can buy a card like that used for a few hundred dollars. A single 1080 card won't train neural networks as fast as the four GPUs I used, but if you're willing to wait a few weeks you'll wind up with similar results.
The Faceswap workflow consists of three basic steps:
- Extraction: chop up a video into frames, detect faces in each frame, and output well-aligned, tightly cropped images of each face.
- Training: Use these extracted images to train a deepfake neural network—one that can take in an image of one person's face and output an image of the other person's face with the same pose, expression, and illumination.
- Conversion: Apply the model trained in the last step to a specific video, producing a deepfake. Once the model is trained, it can be applied to any video containing the specific people it was trained on.
These three steps require radically different amounts of human and computer time. The extraction software runs in a few minutes, but then it can take hours of human labor to check the results. The software flags every face in every extracted image—as well as a fair number of false positives. To get good results, a human has to go through and delete irrelevant faces as well as anything that the software mistook for a face.
In contrast, training is easy to set up and requires very little human oversight. However, it can take days or even weeks of computing time to get a good result. I started training my final model on December 7 and ran it until December 13. It's possible the quality of my deepfake would have improved further with another week of training. And that's with my monster cloud instance and its four high-end graphics cards. If you're doing this kind of work on a personal machine with a single, less-powerful GPU, training a good model could take many weeks.
The final step, conversion, is quick in both human and computer time. Once you have a suitably trained model, outputting a deepfake video file can take less than a minute.
How deepfakes work
Before I describe my Faceswap training process, I should explain how the underlying technology works.
At the heart of Faceswap—and other leading deepfake packages—is an autoencoder. That's a neural network that's trained to take an input image and output an identical image. That might not seem very useful on its own, but as we'll see, it's a key building block for creating deepfakes.
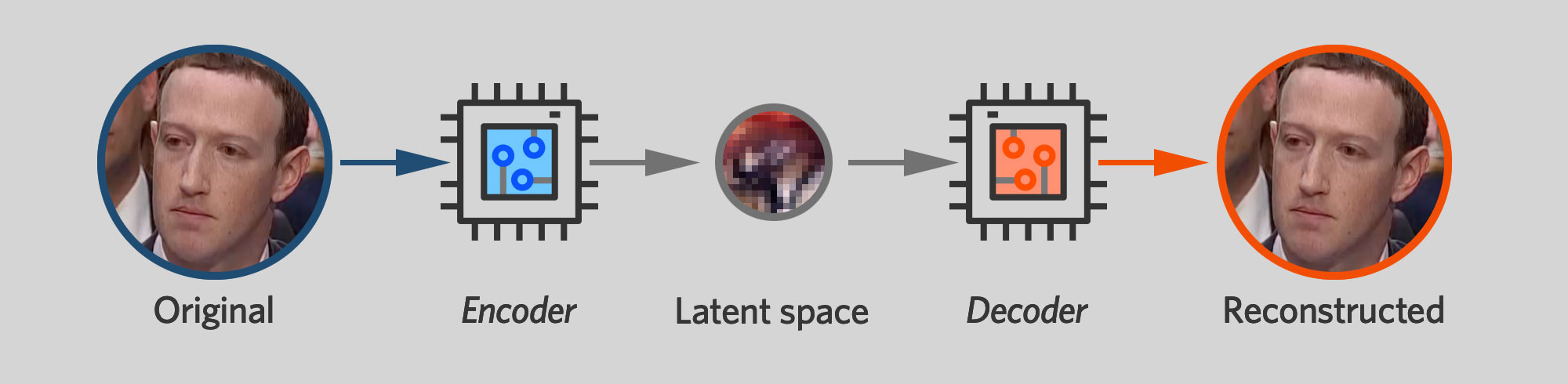
An autoencoder is structured like two funnels with the narrow ends stuck together. One side of the network is an encoder that takes the image and squeezes it down to a small number of variables—in the Faceswap model I used, it's 1024 32-bit floating-point values. The other side of the neural network is a decoder. It takes this compact representation, known as a "latent space," and tries to expand it into the original image.
Artificially constraining how much data the encoder can pass to the decoder forces the two networks to develop a compact representation for a human face. You can think of an encoder as a lossy compression algorithm—one that tries to capture as much information about a face as possible given limited storage space. The latent space must somehow capture important details like which direction the subject is facing, whether the subject's eyes are open or closed, and whether the subject is smiling or frowning.
But crucially, the autoencoder only needs to record aspects of a person's face that change over time. It doesn't need to capture permanent details like eye color or nose shape. If every photo of Mark Zuckerberg shows him with blue eyes, for example, the Zuck decoder network will learn to automatically render his face with blue eyes. There's no need to clutter up the crowded latent space with information that doesn't change from one image to another. As we'll see, the fact that autoencoders treat a face's transitory features differently from its permanent ones is key to their ability to generate deepfakes.
Every algorithm for training a neural network needs some way to evaluate a network's performance so it can be improved. In many cases, known as supervised training, a human being provides the correct answer for each piece of data in the training set. Autoencoders are different. Because they're just trying to reproduce their own inputs, training software can judge their performance automatically. In machine-learning jargon, this is an unsupervised training scenario.
Like any neural network, the autoencoders in Faceswap are trained using backpropagation. The training algorithm feeds a particular image into the neural network and figures out which pixels in the output don't match the input. It then calculates which neurons in the final layer were most responsible for the mistakes and slightly adjusts each neuron's parameters in a way that would have produced better results.
Errors are then propagated backwards to the next-to-last layer, where each neuron's parameters are tweaked once again. Errors are propagated backwards in this fashion until every parameter of the neural network—in both the encoder and the decoder—has been adjusted.
The training algorithm then feeds another image to the network and the whole process repeats once again. It can take hundreds of thousands of iterations of this process to produce an autoencoder that does a good job of reproducing its own input.
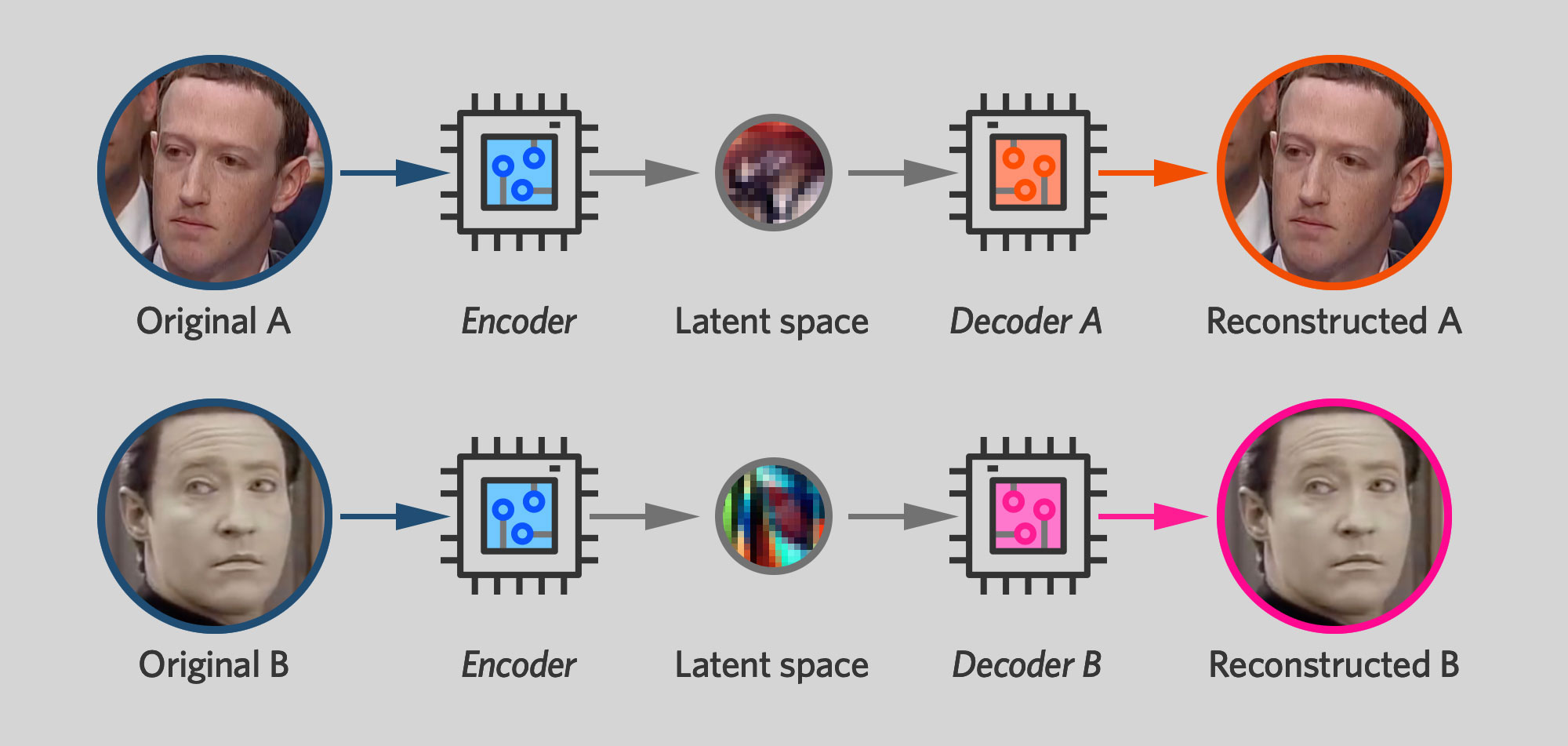
Deepfake software works by training two autoencoders side by side, one for the original face and one for the new face. During the training process, each autoencoder is only shown pictures of one person and is trained to produce images that closely resemble the originals.
However, there's a twist: the two networks use the same encoder unit. The decoders—the neurons on the right-hand side of the network—remain separate, with each trained to produce a different face. But the neurons on the left-hand side of the network have shared parameters that change any time either autoencoder network is trained. When the Zuckerberg network is trained on a Zuckerberg face, that modifies the encoder half of the Data network, too. Each time the Data network is trained on a Data face, the Zuckerberg encoder inherits those changes.
The result is that the two autoencoders have a shared encoder that can "read" either a Mark Zuckerberg face or a Mr. Data face. The goal is for the encoder to use the same representation for things like head angle or eyebrow position whether they're given a photo of Mark Zuckerberg or a photo of Mr. Data. And that, in turn, means that once you've compressed a face with the encoder, you can expand it using either decoder.
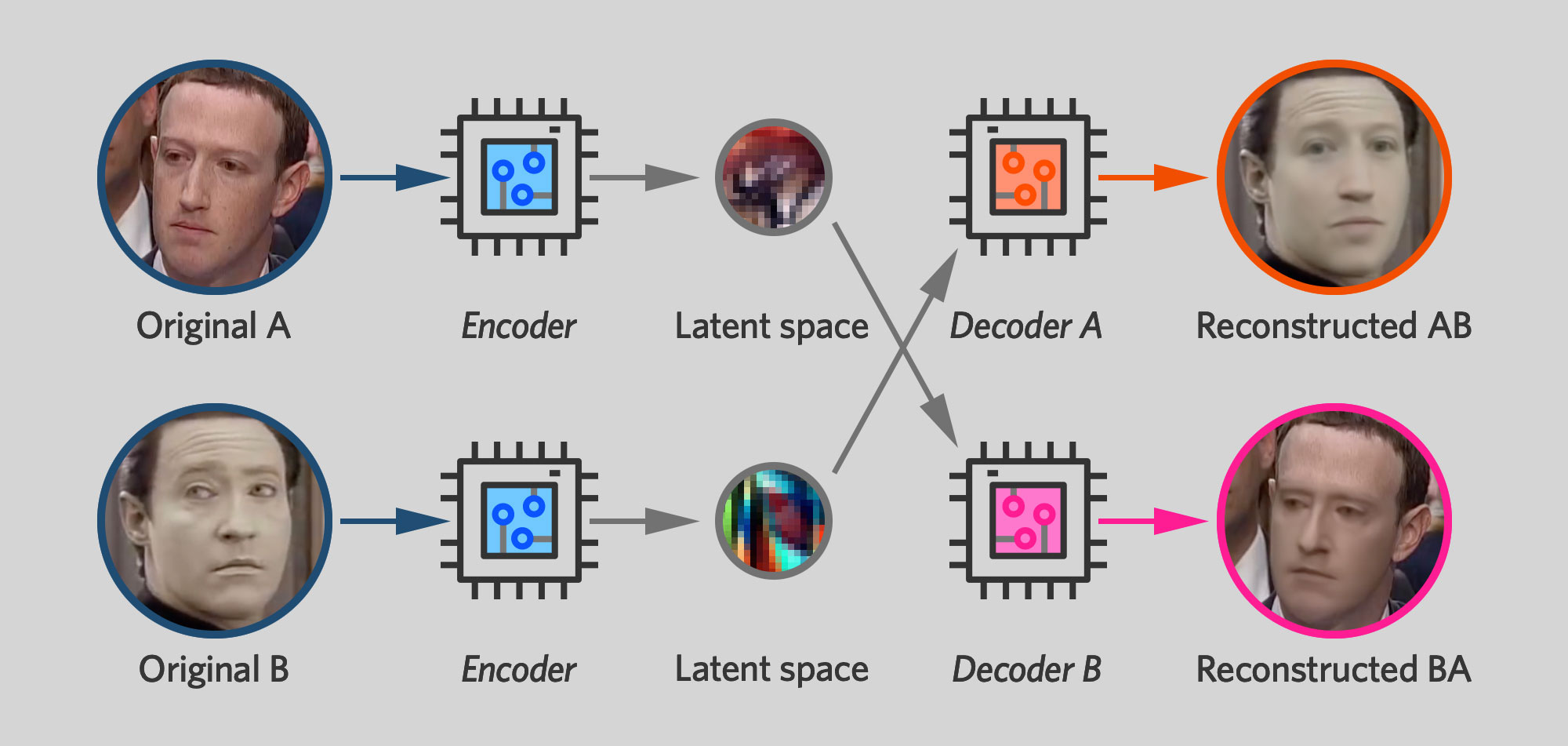
So once you've trained a pair of autoencoders like this, the deepfake step is simple: you switch decoders. You encode a photo of Mark Zuckerberg, but then use the Data decoder in the decoding step. The result is a reconstructed photo of Data—but with the same head pose and expression as in the original photograph of Zuckerberg.
Remember, we said earlier that the latent space tends to capture transient features of a person's face—expression, which direction he's facing, position of eyebrows—while permanent features like eye color or mouth shape are produced by the decoder. This means that if you encode a picture of Mark Zuckerberg and then decode it with the Data decoder, you'll wind up with a face that has Data's permanent features—e.g., the shape of his face—but with the expression and physical expression of the Zuckerberg original.
If you apply this technique to successive frames of a Mark Zuckerberg video, you get a new video of Mr. Data's face performing the same actions—smiling, blinking, turning his head—that Zuckerberg did in the original video.
This is a symmetrical situation. When you train a neural network to input photos of Zuckerberg and output photos of Data, you're simultaneously training the network to take in photos of Data and output photos of Zuckerberg. Faceswap's video conversion tool—the last step in the deepfaking process—includes a helpful "swap model" checkbox that lets the user swap decoders. The result: instead of replacing Data's face for Zuck's face, it does the opposite, producing hilarious videos like this one:
Training Data
In practice, getting good results out of deepfake software isn't easy.
As I mentioned earlier, I collected about seven minutes of Data footage and nine minutes of Zuck footage. I then used Faceswap's extraction tool to chop the video up and obtain tightly-cropped images of both men's faces. The video had around 30 frames per second, but I only extracted about one in six images—a practice recommended by the Faceswap documentation. That's because diversity of images matters more than the raw number, and capturing every frame of a video will mean harvesting an abundance of very similar images.
Faceswap's extraction tool produced a fair number of false positives. It also identified real faces in the backgrounds of some shots. So I spent a couple of hours manually deleting any extracted photos that weren't of my two subjects. At the end of the process, I had 2,598 images of Data and 2,224 faces of Zuckerberg.
At this point, it was finally time to actually train my model. Currently, Faceswap comes pre-packaged with 10 different deepfake algorithms that support different image sizes and have different computing power requirements. At the low end, there's a "lightweight" model that works with face images that are 64 pixels on a side. It can be run on a machine with less than 2GB of VRAM. Other models work with images 128, 256, or even 512 pixels on a side—but doing so require a lot more video memory as well as a lot more training time.
I started out training a model called DFL-SAE that was derived from the algorithms used by DeepFaceLab. However, the Faceswap documentation warned that this model suffered from "identity bleed," where some features of one face would seep into the other. I thought I might be seeing signs of that in my first couple of test videos, so after a day of training I switched to another model called Villain that works with 128-pixel images. The Faceswap guide describes it as "very VRAM intensive" and "a decent choice if you want a higher resolution model without having to adjust any settings."
Then I waited. And waited some more. The training process was still going when I reached my deadline on Friday—after six days of training. At that point, my trained model was producing a pretty good deepfake. The rate of progress seemed to be slowing, but it's possible I would have gotten a better result if I'd had another week of computing time.
The Faceswap software is well designed for long computing jobs. If you run the training command from the graphical user interface, the GUI regularly updates a preview screen showing examples of how the software is rendering Data and Zuck. If you prefer to train from a command line, you can do that too. The Faceswap GUI includes a helpful "generate" button that spits out the exact command you need to execute to train a model with the GUI's current settings.
How good have deepfakes gotten?
During the training process, Faceswap continuously displays a numerical score called the loss for each of the two autoencoders. These figures show how well the Zuckerberg autoencoder can reproduce photos of Zuckerberg—and how well the Data autoencoder can reproduce photos of Data. These numbers still seemed to be declining when I stopped training on Friday, though the rate of progress had slowed to a crawl.
Of course, what we really care about is how well the Data decoder can convert a Zuckerberg face into a Data face. We don't know what these converted images are "supposed" to look like, so there's no way to precisely measure the quality of the result. The best we can do is eyeball it and decide whether we think it looks realistic.
The video above shows the quality of the deepfake at four points in the training process. The December 10 and 12 videos show the partially-trained Villain model. The December 6 video in the upper left is an early test with a different model. In the lower right is the final result. As training progressed, the details of his face got steadily sharper and more lifelike.
On December 9, after about three days of training, I posted a preliminary video to an internal Ars Technica Slack channel. The video looked about like the one in the upper right above. Ars graphics guru Aurich Lawson was scathing.
"Overall it looks pretty bad," he wrote, describing it as "not at all convincing. I have yet to see one of these that doesn't look fake."
I think there's something to his critique. I was surprised at how quickly Faceswap was able to generate face images that were recognizably Brent Spiner rather than Mark Zuckerberg. However, if you look closely enough you can still see telltale signs of digital trickery.
In some frames, the border between Mr. Data's fake face and Mark Zuckerberg's head doesn't quite look right. Occasionally you can see a bit of Zuckerberg's eyebrow peeking out from behind Data's face. In other spots, the edges of the fake face obscure a few pixels of Zuckerberg's ears. These compositing problems could likely be fixed with a bunch of post-processing effort by a human being: someone would need to step through the video frame by frame and adjust the mask for each frame.
The more fundamental problem, however, is that deepfake algorithms don't yet seem very good at reproducing the finest details of the human face. This is fairly obvious if you look at the original and final videos side by side. Faceswap did a surprisingly good job of getting the overall structure of Data's face right. But even after almost a week of training, the face looks kind of blurry, and essential details are missing. For example, deepfake software seems to have trouble rendering human teeth in a consistent way. Someone's teeth will be clearly visible one second. Then a few frames later, their mouths will become a black void with no teeth visible at all.
A big reason for this is that the Faceswapping problem gets exponentially harder at higher resolutions. Autoencoders do fairly well reproducing 64 x 64 pixel images. But reproducing the finer details of 128 x 128 images—to say nothing of images 256 pixels or more on a side—remains a big challenge. This is probably one reason the most impressive deepfakes tend to be fairly wide shots, not closeups of someone's face.
But there's no reason to think this is a fundamental limitation of deepfake technology. Researchers may very well develop techniques to overcome these limitations in the coming years.
Deepfake software is often erroneously described as being based on generative adversarial networks, a type of neural network that enables software to "imagine" people, objects, or landscapes that don't really exist. Deepfakes are actually based on autoencoders, not GANs. But recent progress in GAN technology suggests that there may still be a lot of room for improvement in deepfakes.
When they were first introduced in 2014, GANs could only produce blocky, low-resolution images. But more recently, researchers have figured out how to design GANs that produce photorealistic images as large as 1024 pixels on a side. The specific techniques used in those papers may not be applicable to deepfakes, but it's easy to imagine someone developing similar techniques for autoencoders—or perhaps an entirely new neural network architecture for doing faceswaps.
Keeping deepfakes in perspective
The rise of deepfakes is obviously a real cause for concern. Until recently, it was usually safe for people to take video footage of a human being at face value. The emergence of deepfake software and other digital tools means that we now have to view video footage with skepticism. If we see a video of someone saying something scandalous—or taking their clothes off—we have to consider the possibility that someone manufactured the video to discredit its subject.
Yet my experiment highlights the limitations of deepfake technology—at least in its current incarnation. Plenty of knowledge and effort is needed to produce a completely convincing virtual face. I certainly didn't manage it, and I'm not sure anyone has managed to produce a deepfake video that's truly indistinguishable from the real thing.
Moreover, right now tools like Faceswap only swap faces. They don't swap foreheads, hair, arms, or legs. So even if the face itself is perfect, it may be possible to identify a deepfake video based on other elements that don't quite look right.
However, the limitations of deepfake technology might not last. In a few years, software may be able to produce deepfake videos that are indistinguishable from the genuine article. What then?
In this case, I think it's helpful to remember that other types of media have been fakeable for a long time. For example, it's trivial to create an email screenshot showing someone writing something they didn't actually write. Yet this hasn't led to a rash of people having their careers ruined by fake emails. Neither has it completely discredited email screenshots as a form of evidence in public discourse.
Instead, people know emails can be faked and look for authentication outside the four corners of the email itself. What chain of custody brought the email to the public's attention? Did other people receive copies of the email at the time it was written? Has the purported author of the email admitted he wrote it, or is he claiming it was faked? The answers to questions like this help people decide how seriously to take a published email.
Fool me once
So too with videos. There may be a short window where tricksters can destroy someone's career by publishing a video showing them saying or doing something outrageous. But soon the public will learn to view a video with skepticism unless it has a clear chain of custody, corroborating witnesses, or other forms of authentication.
I expect this will be true even for the most outrageous abuse of deepfake technology: inserting someone's face into a pornographic video. This is obviously disrespectful and inappropriate. But people have also raised concerns that videos like this could destroy the reputations and careers of their subjects. I think that's probably wrong.
After all, the Internet is already awash in Photoshop images of (mostly female) celebrities' heads affixed to porn stars' bodies. This causes women understandable distress. But the public doesn't automatically conclude that these women posed for nude photos—we know that Photoshop exists and can be used to make fake photos.
So too with deepfake porn videos. It's obviously not nice for someone to make a fake porn video of you. But releasing a deepfake video of someone won't have the same devastating impact that leaking a genuine sex video might. Absent supporting evidence of a video's authenticity, the public will learn to assume that it is likely fake.
Indeed, Faceswap's Matt Tora tells me that this is a big part of his motivation for creating the software. He believes that the development of faceswapping software is inevitable. He hopes that creating a user-friendly, open source faceswapping tool will help to demystify the technology and educate the public on its capabilities and limitations. That, in turn, will help us get more quickly to the point where the public applies an appropriate degree of skepticism to videos that might be fake.
In the long run, the larger risk may be that public attitudes swing too far in the opposite direction: that the possibility of deepfakes completely destroys public trust in video evidence. Certain politicians are already in the habit of dismissing media criticism as "fake news." That tactic will only become more effective as public awareness of deepfake technology grows.
https://news.google.com/__i/rss/rd/articles/CBMiaGh0dHBzOi8vYXJzdGVjaG5pY2EuY29tL3NjaWVuY2UvMjAxOS8xMi9ob3ctaS1jcmVhdGVkLWEtZGVlcGZha2Utb2YtbWFyay16dWNrZXJiZXJnLWFuZC1zdGFyLXRyZWtzLWRhdGEv0gFuaHR0cHM6Ly9hcnN0ZWNobmljYS5jb20vc2NpZW5jZS8yMDE5LzEyL2hvdy1pLWNyZWF0ZWQtYS1kZWVwZmFrZS1vZi1tYXJrLXp1Y2tlcmJlcmctYW5kLXN0YXItdHJla3MtZGF0YS8_YW1wPTE?oc=5
2019-12-16 12:50:00Z
CBMiaGh0dHBzOi8vYXJzdGVjaG5pY2EuY29tL3NjaWVuY2UvMjAxOS8xMi9ob3ctaS1jcmVhdGVkLWEtZGVlcGZha2Utb2YtbWFyay16dWNrZXJiZXJnLWFuZC1zdGFyLXRyZWtzLWRhdGEv0gFuaHR0cHM6Ly9hcnN0ZWNobmljYS5jb20vc2NpZW5jZS8yMDE5LzEyL2hvdy1pLWNyZWF0ZWQtYS1kZWVwZmFrZS1vZi1tYXJrLXp1Y2tlcmJlcmctYW5kLXN0YXItdHJla3MtZGF0YS8_YW1wPTE
Bagikan Berita Ini














0 Response to "I created my own deepfake—it took two weeks and cost $552 - Ars Technica"
Post a Comment